Support Vector Machine
Machine Learning Model - Support Vector Machine
Support Vector Machine offers very high accuracy compared to other classifiers such as logistic regression and decision trees.
How does SVM work?
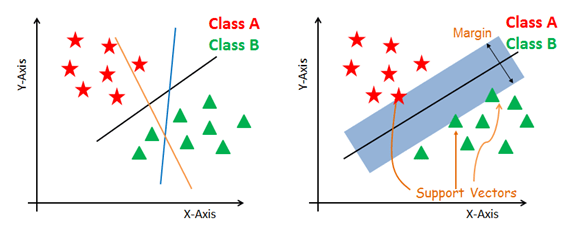
The main objective is to segregate the given dataset in the best possible way.
The distance between the nearest points is known as the margin.
The objective is to select a hyperplane with the maximum possible margin between
support vectors in the given dataset.
SVM searches for the maximum marginal
hyperplane in the following steps:
1. Generate hyperplanes which segregate the classes in the best way.
2. Select the right hyperplane with the maximum segregation from the nearest data points.
Results :
When categorizing the movie data into success/failure categories, the model
had the following accuracy scores:
Training Data Score: 0.8786044855820577
Testing Data Score: 0.8826040554962646
Hyperparameter tuning {'C': 50, 'gamma': 0.0001} 0.8850096104439835
SVM is the second most accurate Model after Random Forest.
Hyperparameter tuning improved accuracy slightly.